Temporal action detection

We developed deep learning methods to automatically discover action segments from the untrimmed videos.
- Introduction
The temporal action detection task aims to automatically locate the start and end times of actions in untrimmed videos and predict the corresponding action categories. This task has a wide range of applications in security surveillance, highlight extraction, and intelligent video editing.
The temporal action detection task consists of two sub-tasks: action localization and action classification. Depending on whether these two sub-tasks are handled separately, existing methods can be grouped into two categories. The first category of methods first generates proposals that could be action segments and then uses an individual action recognition network to determine the class of each proposal. This type of approach usually provides better performance, but the separation of the two sub-tasks introduces an additional computational burden for training and testing. The second class of approaches combines the classification and localization tasks into a unified model for joint training and testing. This type of approach runs faster but does not perform as well in terms of performance. This is because most jointly trained models do not take into account the different nature of the features required for the two tasks. The action classification task requires highly discriminative and robust features, while the action localization task requires features that are sensitive to location. To tackle this problem, we proposed a new attention mechanism to provide representations with different properties for the two sub-tasks of action classification and action localization, respectively.
In addition, all of the above temporal action detection methods need to be trained by supervised learning, so a large number of videos need to be manually annotated for training data. The manual annotation process is not only time-consuming and laborious but also the annotation of the same action may vary greatly from one person to another. In order to reduce the manual annotation cost, we investigated the weakly supervised temporal action detection method and analyzed the impact of pseudo labels on the weakly supervised model. Then we proposed an overconfidence suppression strategy and a pseudo label correction strategy to reduce the negative impact of pseudo labels on the model performance.
- Video representation learning for temporal action detection using global-local attention
Video representation is of significant importance for temporal action detection. The two sub-tasks of temporal action detection, i.e., action classification and action localization, have different requirements for video representation. Specifically, action classification requires video representations to be highly discriminative, so that action features and background features are as dissimilar as possible. For action localization, it is crucial to obtain information about the action itself and the surrounding context for accurate prediction of action boundaries. However, the previous methods failed to extract the optimal representations for the two sub-tasks, whose representations for both sub-tasks are obtained in a similar way.
In this study, we proposed a Global-Local Attention (GLA) mechanism to produce a more powerful video representation for temporal action detection without introducing additional parameters. The global attention mechanism predicts each action category by integrating features in the entire video that are similar to the action while suppressing other features, thus enhancing the discriminability of video representation during the training process. The local attention mechanism uses a Gaussian weighting function to integrate each action and its surrounding contextual information, thereby enabling precise localization of the action.
The effectiveness of GLA is demonstrated on THUMOS'14 and ActivityNet-1.3 with a simple one-stage anchor-free network (OAF-Net), achieving state-of-the-art performance among the methods using only RGB images as input. The inference speed of the proposed model reaches 1373 FPS on a single Nvidia Titan Xp GPU. The generalizability of GLA to other detection architectures is verified using R-C3D and Decouple-SSAD, both of which achieve consistent improvements. The experimental results demonstrate that designing representations with different properties for the two sub-tasks leads to better performance for temporal action detection compared to the representations obtained in a similar way.
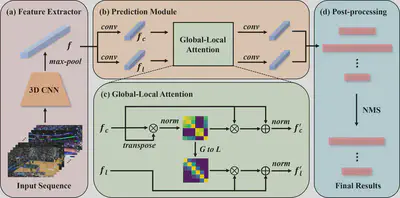
Overview of OAF-Net. (a) Feature extractor. It is composed of a 3D CNN (C3D) followed by a max-pooling layer. (b) Prediction module. The classification and localization branches generate $k$+1 ($k$ classes plus background) classification scores and localization offsets for each feature point, respectively. (c) GLA module. A global attention map is created by calculating the cosine similarity between every two feature points for classification. A local attention map is produced from the global attention map for localization. (d) Post-processing. All the predictions are filtered by the NMS algorithm to give the final results.
Read our paper for more details:
Yiping Tang, Yang Zheng, Chen Wei, Kaitai Guo, Haihong Hu, Jimin Liang*, Video Representation Learning for Temporal Action Detection Using Global-Local Attention, Pattern Recognition, 134:109135, 2023.
- Towards better utilization of pseudo labels for weakly supervised temporal action localization
Weakly supervised temporal action localization (WS-TAL) aims to simultaneously recognize and localize action instances of interest in untrimmed videos with the use of the video-level label only. Some works have demonstrated that pseudo labels play an important role for performance improvement in WS-TAL. Since pseudo labels are inevitably inaccurate, direct adoption of noisy labels can lead to inappropriate knowledge transfer. Although some previous studies have shown the benefits of using only reliable pseudo labels, performance improvement is still limited. In this work, we experimentally analyze how the noise in pseudo labels affects model performance within the self-distillation framework. Motivated by the finding that incorrect pseudo labels with large confidence scores have a significant impact on performance, we propose the overconfidence suppression (OCS) strategy to mitigate the effect of the overconfident pseudo labels, and thus prevent over-fitting of the student model. In addition, a simplified contrast learning method is utilized to fine-tune the feature representation by increasing the separation of the foreground and background snippets. Equipped with the proposed methods, the benefits of pseudo labels can be better exploited and allow the model to achieve state-of-the-art performance on THUMOS'14 and ActivityNet-1.2 benchmarks.
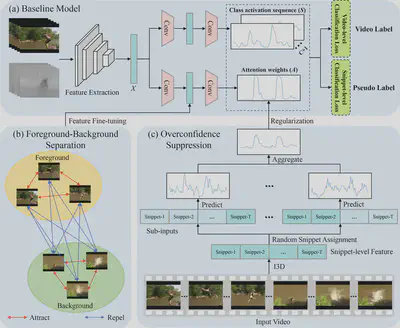
Overview of our method. (a) Baseline model. (b) Foreground-background separation strategy. (c) Overconfidence suppression strategy.
Read our paper for more details:
Yiping Tang, Junyao Ge, Kaitai Guo, Yang Zheng, Haihong Hu, Jimin Liang*, Towards Better Utilization of Pseudo Labels for Weakly Supervised Temporal Action Localization, Information Sciences, 623:693-708, 2023.
Jimin Liang
Professor of Electronic Engineering
My research interests include artificial intelligence and computer vision.