Reasoning segmentation in remote sensing
We developed a new reasoning-driven segmentation framework for remote sensing that bridges abstract semantic understanding and precise pixel-level delineation.
Introduction
Remote sensing image segmentation has made major progress in recent years, but most existing methods still assume that the target can be specified explicitly. In other words, the model works best when the user asks for a building, a road, or a vehicle with clear visual attributes. However, many real-world remote sensing queries are not phrased this way. A user may instead ask for the sports area most suitable for hurdle racing or the facility that should be monitored for hazardous leaks. These queries cannot be solved by category matching alone. They require semantic understanding, spatial reasoning, and precise delineation at the pixel level.
This challenge motivates the emerging task of reasoning segmentation in remote sensing. Compared with conventional segmentation or referring segmentation, reasoning segmentation requires the model not only to identify visual patterns, but also to infer which region satisfies an implicit concept, a function, or a piece of geospatial logic.
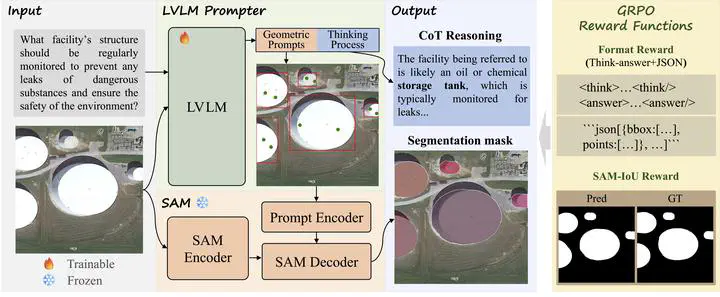
In this work, we propose Think2Seg-RS, a new framework that explicitly separates reasoning from segmentation execution. Instead of forcing a single end-to-end model to directly output masks from language, we let a large vision-language model reason about the scene and generate structured geometric prompts, and then let a frozen Segment Anything Model (SAM) produce the final segmentation mask. This design allows the system to first understand and then act, making the overall process more interpretable, more modular, and better aligned with the nature of the task.
Why Existing Pipelines Are Not Enough
Existing large vision-language models are strong at instruction following and multimodal reasoning, but they are not naturally designed for precise dense prediction in remote sensing imagery. Directly asking them to output segmentation masks is difficult because high-level reasoning and low-level geometric delineation are very different problems. On the other hand, SAM is highly effective at promptable segmentation, but it depends critically on the quality of the input prompts.
This creates a key bottleneck: the real challenge is not only how to segment, but how to convert abstract reasoning into reliable geometric instructions.
Some recent methods attempt to solve this by supervising models with pseudo boxes or pseudo points. While useful, these approaches still constrain the model to imitate handcrafted prompt patterns. In our view, this is too restrictive for reasoning segmentation, where multiple prompt configurations may lead to good masks and where the best prompting strategy should ideally be discovered automatically.
Our Method: Think2Seg-RS
Think2Seg-RS follows a decoupled reasoning-execution paradigm.
- A trainable large vision-language model receives the remote sensing image and the natural language query.
- The model first generates a short reasoning process to interpret the intent of the query in the scene context.
- Based on that reasoning, it outputs structured geometric prompts, including bounding boxes and positive points.
- A frozen SAM2 model then takes these prompts and produces the final segmentation mask.
The core idea is that language reasoning should guide prompt generation, while segmentation should remain the job of a universal execution engine. This avoids compressing rich semantic reasoning into a single latent mask token or a monolithic decoder, which often leads to an information bottleneck and weak geometric grounding.
Another important feature of our method is its training strategy. Instead of requiring costly box-point supervision, we train the language model with a mask-only GRPO reinforcement learning objective. The model is rewarded according to two simple signals:
- whether the output format is valid and can be parsed correctly
- whether the final mask generated by SAM overlaps well with the ground truth
This means the model learns prompt generation through the final segmentation outcome, rather than through imitation of manually designed intermediate prompts. As a result, it can explore more effective ways to convert reasoning into actionable geometric instructions.
Key Findings
Our experiments show that Think2Seg-RS achieves state-of-the-art performance on the EarthReason benchmark, demonstrating the effectiveness of learning reasoning-aware prompts through direct segmentation feedback.
Beyond the benchmark improvement, the study also reveals several insights that we believe are important for future remote sensing reasoning systems:
- Reasoning segmentation is fundamentally different from instance-level grounding. Semantic-level reasoning often asks the model to identify all regions that satisfy a concept, while instance-level tasks require explicit separation between individual objects.
- Smaller segmenters can sometimes work better than larger ones. Under semantic-level supervision, compact SAM variants may avoid the over-segmentation behavior introduced by excessive sensitivity to local textures.
- Negative prompting is unstable in complex aerial scenes. While negative points are useful in interactive segmentation, they are much harder to optimize automatically in heterogeneous remote sensing backgrounds.
These findings suggest that improving reasoning segmentation is not only a matter of scaling models, but also of aligning the reasoning module, the prompt interface, and the execution engine with the annotation granularity and task objective.
Why This Matters
We see this work as a step toward a more natural form of geospatial intelligence. Traditional segmentation asks: what object category does each pixel belong to? Referring segmentation asks: which region matches this explicit phrase? Reasoning segmentation goes one step further and asks: which region best satisfies a concept, a function, or a multi-step spatial judgment?
This shift is important because real users often think in semantic or functional terms rather than in strict object labels. If remote sensing systems are to become more useful in scientific analysis, urban management, environmental monitoring, and open-world geospatial search, they must be able to reason before they segment.
Think2Seg-RS provides a practical way to move in this direction. By decoupling reasoning and execution, and by optimizing the reasoning module with direct segmentation feedback, the framework offers a scalable and interpretable path toward next-generation remote sensing foundation models.
Read our paper for more details:
Xu Zhang, Junyao Ge, Yang Zheng, Kaitai Guo, Jimin Liang*, Bridging Semantics and Geometry: A Decoupled LVLM-SAM Framework for Reasoning Segmentation in Remote Sensing, ISPRS Journal of Photogrammetry and Remote Sensing, 2026.
Jimin Liang
Professor of Electronic Engineering
My research interests include artificial intelligence and computer vision.