RSVP-EEG classification: Simpler is better
We developed a prior-guided framework for RSVP-EEG decoding and found that, for this task, a simple MLP can match or even outperform Transformer-based models.
Introduction
Rapid serial visual presentation (RSVP) is a classic paradigm in EEG-based brain-computer interfaces. It has been widely used in applications such as surveillance, rapid image search, and intelligent screening, where a subject watches a fast stream of images and rare target stimuli evoke a characteristic P3 response. The key challenge is to determine, from a single EEG trial, whether the current stimulus is a target or not.
This sounds straightforward in principle, but RSVP-EEG decoding is in fact a difficult problem. The EEG signal is weak, noisy, and highly imbalanced, because target trials are much rarer than non-target trials. More importantly, RSVP data have two intrinsic characteristics that are often underestimated. First, the recorded EEG is a mixture of multiple neural components rather than a clean P3 waveform. Second, because images are presented rapidly, adjacent trials overlap in time, meaning that non-target trials close to a target may still contain residual target-related activity.
These observations motivated our work. In recent years, Transformer-based architectures have become increasingly popular in EEG decoding, following the broader trend in machine learning. Naturally, we also began from this direction. But as we pushed the model design further, a more interesting story emerged: what really matters in RSVP-EEG decoding may not be architectural complexity, but whether the model is aligned with the structure of the neural signal itself.
From Transformer Design to a More Fundamental Question
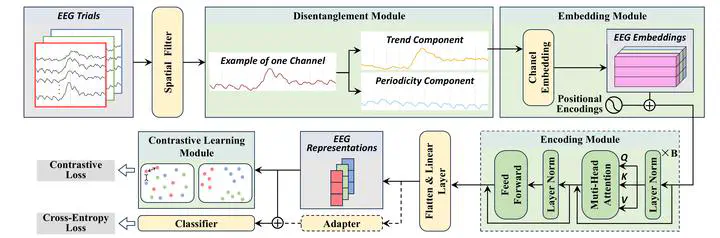
Our initial framework, named DisCo-Former, was built as a Transformer-based model for RSVP-EEG classification. However, it was not a generic Transformer applied blindly. We designed it around three neurophysiological priors:
- Trend-periodicity disentanglement, to separate the low-frequency trend component dominated by P3 from oscillatory and other periodic activity.
- Channel-level embedding, to preserve full-trial temporal structure instead of fragmenting EEG into local temporal patches.
- Contrastive learning for adjacent non-targets, to explicitly address the label ambiguity caused by target-adjacent overlap.
With these components, DisCo-Former achieved state-of-the-art performance on RSVP-EEG benchmarks. At first glance, this seemed to validate the effectiveness of Transformer-based modeling.
But when we looked more closely at the trained model, the evidence pointed in another direction.
The self-attention maps became nearly uniform, and the value projection weights shrank toward zero. In other words, the attention mechanism itself was collapsing and contributing very little useful computation. The model was performing well, but not because the Transformer was discovering rich token-to-token relations. Instead, most of the benefit appeared to come from the prior-guided representation design around it.
This led to a natural and important question:
Do we really need a Transformer for RSVP-EEG decoding?
Our Answer: DisCo-MLP
To answer this question, we removed the Transformer encoder entirely while retaining all the other prior-guided modules. The resulting simplified model, DisCo-MLP, is a pure multilayer perceptron pipeline.
This design may appear surprisingly simple, but it is well matched to the characteristics of RSVP-EEG. In this task, the precise temporal position of the P3 response is critical. Unlike convolutional or token-based architectures that tend to emphasize local patterns or fragmented representations, the MLP-based backbone in our framework preserves full-trial temporal information more directly. Combined with the disentanglement module and contrastive learning strategy, it provides a clean and effective way to model RSVP signals without relying on attention.
What happened next was the most striking result of the study: DisCo-MLP matched or even outperformed DisCo-Former across within-subject, cross-subject, and cross-dataset evaluations.
This is the central message of the work. The Transformer was not the real source of performance gain. The gain came from modeling the signal structure correctly.
Why This Matters
This finding is meaningful for two reasons.
First, it provides one of the clearest empirical demonstrations, in the RSVP-EEG setting, of attention collapse in Transformer-based neural decoding. The model can still perform well, but the attention mechanism itself may degenerate into an almost uniform and functionally redundant operation.
Second, it suggests a broader lesson for EEG research: more complex architectures do not automatically produce better neural decoding. When the data are noisy, weakly supervised, and strongly structured by neurophysiological mechanisms, a simpler model that respects those properties may be a better choice than a more fashionable architecture.
In this sense, our work is not just about proposing a better classifier. It is about challenging a common assumption. Rather than asking how to make RSVP-EEG models deeper or more complicated, we ask how to make them more faithful to the signal generation process itself.
Key Technical Insights
Beyond the main architectural conclusion, the study also provides several concrete insights into effective RSVP-EEG decoding:
- Disentanglement matters. Separating trend and periodicity components helps isolate the task-relevant P3 structure from other oscillatory activities.
- Adjacent non-targets should not be treated as ordinary negatives. Non-target trials near targets are often contaminated by target-related responses, and modeling this ambiguity improves decoding.
- Global temporal preservation is crucial. RSVP decoding depends strongly on time-locked neural dynamics, so preserving whole-trial structure is more useful than aggressively fragmenting the signal into local tokens.
- Transfer matters in practice. The framework performs strongly not only within subject, but also in cross-subject and cross-dataset settings, which are much closer to realistic BCI deployment scenarios.
These observations support a perspective shift: effective EEG decoding should be built around the structure of the paradigm and the signal, rather than around architectural novelty alone.
Conclusion
This work began as an attempt to build a strong Transformer-based RSVP-EEG decoder, but it ended with a more fundamental conclusion. Once the important characteristics of RSVP-EEG are modeled properly, the self-attention mechanism becomes far less important than expected. A few-layer MLP, when grounded in neurophysiological priors, can reach or even surpass Transformer-level performance.
For us, this is the most interesting part of the story. Sometimes the real scientific progress does not come from adding more complexity, but from discovering which parts of the complexity were unnecessary in the first place.
Read our paper for more details:
Ziyuan Zhang, Yang Zheng, Kaitai Guo, Jimin Liang*, Minghao Dong, A Few-Layer Multilayer Perceptron is Worth Attention for EEG Classification in Rapid Serial Visual Presentation Task, International Journal of Neural Systems, 2026.
Jimin Liang
Professor of Electronic Engineering
My research interests include artificial intelligence and computer vision.