Simpler is better: Rethinking Attention in EEG Decoding
Our paper on EEG Classification for RSVP Task has been published by International Journal of Neural Systems - March 23, 2026.
Our latest paper, “A Few-Layer Multilayer Perceptron is Worth Attention for EEG Classification in RSVP Task,” has been published in the International Journal of Neural Systems .
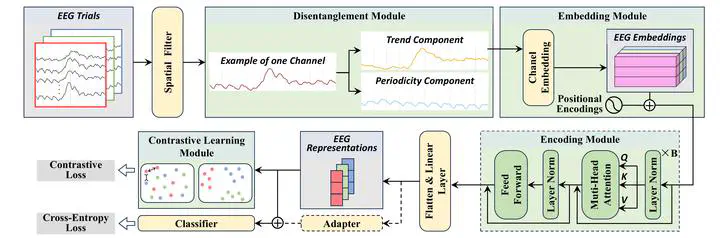
In recent years, Transformer-based models have rapidly become the dominant paradigm across machine learning. Naturally, we followed this trend and set out to design increasingly sophisticated Transformer architectures for EEG decoding in rapid serial visual presentation (RSVP) tasks.
But something unexpected happened.
Despite extensive architectural engineering, performance gains remained limited. Even more intriguingly, deeper analysis revealed a surprising phenomenon: the Transformer’s attention mechanism collapsed. Instead of learning meaningful dependencies, the attention maps became nearly uniform, and the model effectively degenerated into a simple feedforward structure.
This observation led us to a fundamental question:
Do we really need complex architectures for EEG decoding?
To answer this, we removed the Transformer entirely and replaced it with a lightweight multilayer perceptron (MLP), while preserving domain-specific modeling components. The result was striking:
- The simplified MLP model matched or even outperformed the Transformer-based model
- It achieved state-of-the-art performance across multiple datasets and settings
- It did so with significantly lower complexity and better interpretability
Our findings suggest that, for RSVP-EEG decoding, performance is not driven by architectural complexity, but by how well the model aligns with the underlying neural signal structure.
In this sense, the word “attention” in our title carries a double meaning:
- It challenges the dominance of the Transformer attention mechanism
- And it calls for the community’s attention to a simpler, more effective alternative
This work contributes one of the first empirical studies demonstrating attention collapse in EEG Transformers, and highlights a broader lesson:
Sometimes, the simplest model is not just sufficient — it is better.
Jimin Liang
Professor of Electronic Engineering
My research interests include artificial intelligence and computer vision.