Bridging Semantics and Geometry: A Decoupled LVLM–SAM Framework for Reasoning Segmentation
Our paper on reasoning segmentation has been published by ISPRS Journal of Photogrammetry and Remote Sensing - April 25, 2026.
Our latest paper, “Bridging Semantics and Geometry: A Decoupled LVLM-SAM Framework for Reasoning Segmentation,” has now been published in the ISPRS Journal of Photogrammetry and Remote Sensing.
Remote sensing segmentation has made impressive progress, but most existing systems still work best when the target is explicitly described: a building, a road, a vehicle, or an object with a clear visual cue. Real-world queries are often much harder. A user may ask for the sports area most suitable for hurdle racing, or the facility that should be monitored for hazardous leaks. These are not simple category labels. They require reasoning.
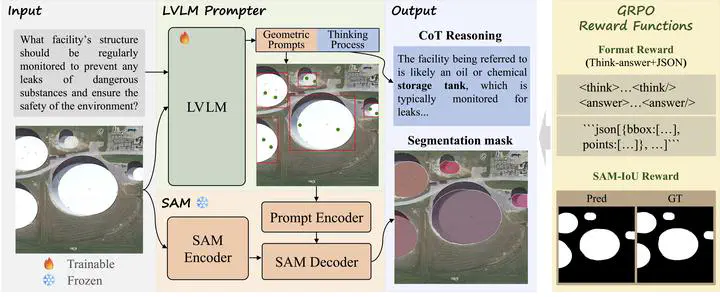
This is the problem we set out to address. In this work, we propose a new remote sensing reasoning segmentation framework, Think2Seg-RS, designed to bridge abstract semantic reasoning and precise pixel-level delineation.
The key idea is simple but powerful: instead of forcing one model to do everything end-to-end, we decouple the problem into two stages. A large vision-language model first interprets the query, reasons about the scene, and generates structured geometric prompts. A frozen Segment Anything Model (SAM) then turns those prompts into the final mask. In other words, the model does not merely “look and segment”; it first thinks, then acts.
This decoupled design brings two important advantages. First, it avoids the information bottleneck of directly squeezing high-level reasoning into a mask token or a monolithic decoder. Second, it makes the system far more modular and scalable: the language model is responsible for semantics and spatial logic, while SAM remains the execution engine for high-quality segmentation.
To make this work, we further introduce a mask-only reinforcement learning strategy based on GRPO. Rather than supervising the model with handcrafted boxes or points, we let the final segmentation quality speak for itself. If the generated prompts lead SAM to a better mask, the model is rewarded. This allows the system to learn how to convert reasoning into actionable geometric instructions through direct segmentation feedback.
Experiments show that this strategy is highly effective. Think2Seg-RS achieves state-of-the-art performance on the EarthReason benchmark and also transfers well across multiple remote sensing referring segmentation datasets. Beyond the benchmark gains, the study also reveals several interesting insights: semantic-level reasoning segmentation is fundamentally different from instance-level grounding, smaller segmenters can sometimes work better than larger ones under semantic supervision, and negative prompting is far less stable in complex aerial scenes than one might expect.
More broadly, this work is our attempt to move remote sensing segmentation one step closer to real human queries. Instead of asking the model only what object is this?, we want it to answer which region best satisfies a concept, a function, or a piece of spatial reasoning? We believe this shift from direct recognition to reasoning-driven delineation is an important direction for next-generation geospatial intelligence.
An AI-generated public overview of this paper is also available on gist.science. That page was not created or edited by us, but readers may still find it a useful supplementary summary.
Jimin Liang
Professor of Electronic Engineering
My research interests include artificial intelligence and computer vision.